大数据(2)-数据处理-格式
数据的输入的原始存储格式,和内存中的组织形式,是决定数据处理性能的关键。
格式的场景
所以大数据中很多技术是关于格式的,或新或老的一些技术,比如
存储(on-disk)的格式:Parquet,ORC,Avro,CSV,JSON…
通信(on-wire)的格式:Protobuf,Avro,JSON…
计算(In-memory)的格式:Arrow
共性来说,就是数据的组织形式,行式或列式,数据的编码/压缩格式,不同场景的话,各有所长。
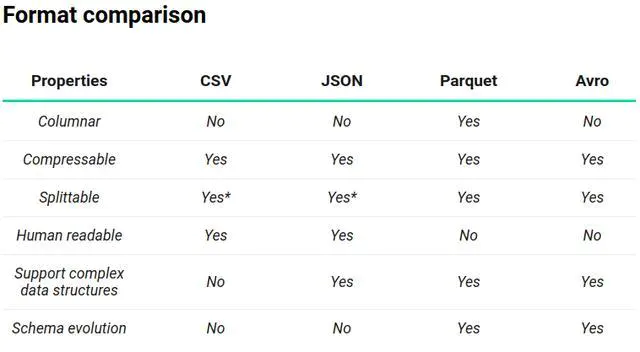
如最熟悉的CSV,JSON都是无压缩的字符串,JSON的结构化更适合阅读。
Parquet,ORC都是列式,面向机器,因为计算过程往往是按列的,所以存储上按列可以减少随机访问,提高IO。
Avro是行式的,因为有时列持久化需要等所有或一大波数据才能持久化一次,而按行更符合通信流,适合通信持久化。
无论批处理还是流处理了,需要处理合适的输入的格式。流处理情况下大部分还是需要处理行式的,批处理则更适合列式。
计算上还需要用列格式,所以流式处理上需要有一个行到列的反序列化,这会降低一定的吞吐。
性能 or 扩展性
计算类型格式理论上是一个很私密的东西,和之前讨论的计算状态一样。如何很好的将计算(Stateless)与 格式分开是不容易的。俗称“存算分离”,分离清晰,可以快速横向扩展,有更好的可扩展性,但可能会使性能下降。这中间有个度需要结合自己的需求场景把握。
提到性能,参考一下当前流行的计算组件的速度 https://h2oai.github.io/db-benchmark/
除了Spark,Pandas这些耳熟能详的,我们看看前几名:
Clickhouse是OLAP数据库,主场景是存算合一的数据库,比如交互式查询
R语言的 data.table 主场景是科学计算
Julia的Dataframe.jl 主场景是科学计算 https://dataframes.juliadata.org/stable/
都在自己的计算场景下,也没有开放格式,使得内部处理和格式更紧密,更容易优化性能。
Polars是基于Apache Arrow是目前一个面向计算的内存格式的项目,是一个Libary。Arrow是一个计算格式的Libary,目前很火。
计算与格式
Hadoop MapReduce时代计算格式可以认为和持久化格式相同,中间结果都存储在HDFS中,所以内存的开销很小,也符合最早Hadoop的定位,整合“弱鸡”的计算能力。100%纯净的“存算分离”,但也足以可见,计算格式和持久化格式最初是一致的,这样的IO节省了格式之间的转换。
但速度需求永远是大数据的刚性需求,用内存空间换时间的Spark,很快取代了MapReduce,其区别就是Spark在内存中定义计算,并可以对内存中的计算分布式交换(Shuffle),大大提升了计算性能。
但Spark的Dataframe本身是封闭的与计算过程耦合紧密,不光Spark,各个组件都有优先自己场景的格式。大家很快意识到,格式和计算确实紧密,也就是格式一定程度决定了计算的速度,而数据应用的Python,Java程序员并不想自己再来一套这个。
于是一个C++ Arrow项目诞生了,其定位是一个计算格式的通用库,统一计算格式,因为是C++写的,性能自然又要高Java一个量级,本身又是库,所以提供了各种语言的接口,让大家专注于计算部分,然后对外提供FFI到各种组件。
总结
格式上的选择也很多,存储容量,成本,IO,转换的开销,延迟都在不同的数据场景下有不同的偏爱。方案或者架构的本身就是不断做选择题,MAX(客户预算-产品成本)就是不断求解的过程。还是那句话,适合的才是最好的。尤其是大数据领域,大坑太多,请平衡好成本。