大数据(1)-流式处理-状态
转行搞了三年大数据,计划写些的东西,对这个方向总结一下,包括架构,工具,格式,库等等。
最近准备造轮子,就先从一些目前最常见的流式数据处理手段开始。
Spark & Flink
Spark,Flink是最知名的通用数据处理工具,不限定场景,不限定数据量。支持分布式,支持自定义状态,灵活定义数据处理逻辑(执行计划)。
当然缺点就是:人工参与程度大,速度慢,系统臃肿。
缺点与优点是相互取舍的,因为本身就是通用平台,不能与业务场景过分绑定,所以很多功能在实际使用时是不需要的,比如只用20%功能,但也有80%的功能拖慢了速度。
另外磁盘和网络IO,也是持久化,分布式必须的。
调用方式:因为两者定位都是数据平台,都是异步的网络API,即使有SDK,也相当于客户端封装再异步调用。
状态
Flink (https://flink.apache.org/) 举例,他官方描述就是 Stateful Computations over Data Streams
顾名思义,有两个东西,一个是Data Stream,一个是Computation State,这个是任何流处理系统的共识抽象。
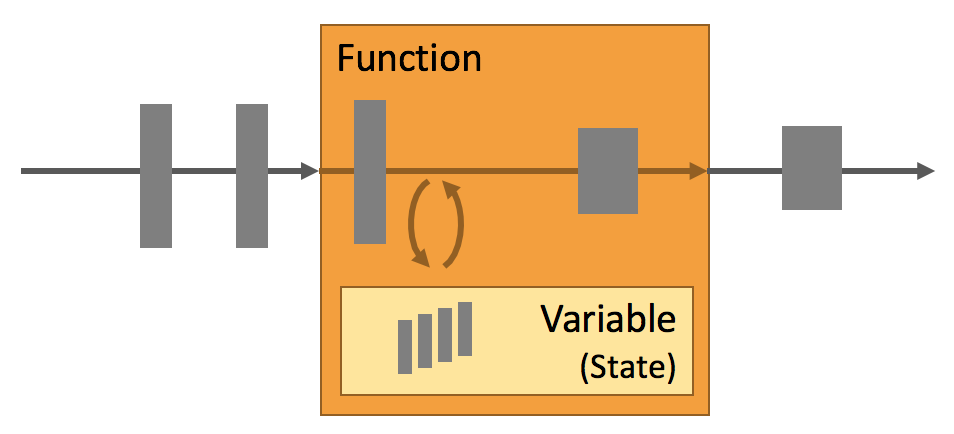
最简单理解就是上图,流入一些数据A,B经过处理系统,数据会通过当前定义的函数或执行计划,改变内部存储的State(比如内置RocksDB),数据与State相互作用后,输出了C,D。
基于这个抽象,思考几个简单的场景和问题:
State与Function的关系:State是Computation State,所以顾名思义和计算函数Function是共生的。举个最简单的例子,我要做一个累加的状态,那么A,B,C进来,Function就是 ++,State就是存储 ++ 结果的持久化内容。这样很容易理解吧。
分离计算与计算对应的状态,其好处就是可以将计算并发(快),读写共享状态(慢),在处理海量数据时,更容易进行扩展,比如A,B在一个线程上相加,C,D在另外一个线程相加,然后State再加到一起,或者说每个线程都可以有个State,相加后,在处理合并State的的步骤。
而具体用那种策略更好呢?其实就是一种执行计划,它是根据你定义的计算过程而制定的。甚至可以在计算过程中根据流入数据的情况进行动态调整。
流式处理里什么事后不需要状态(Stateless),简单的格式转换,丢弃,没有信息的增加,对上线文无关,都可以不需要状态。通常不需要状态的,我理解是计算无关的,不是流式计算引擎的重点。
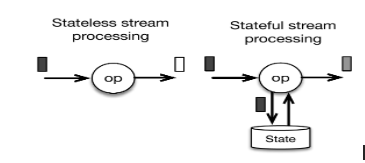
Spark和Flink都内置了大量的计算函数和对应的State,一般来说只用内置计算函数时,对其状态是不太感知的。但作为通用计算引擎,提供自定义计算是必需功能,那此时也必定涉及到State的定义。
通常我们使用的UDFs(User Defined Functions)就是无状态的(Stateless),只定义函数,不定义状态。
而UDAFs(User Defined Aggregate Functions)就是要定义,在给定聚合和Key情况下,状态的变化。
而更灵活的自定义聚合函数和State则还需要定义状态迁移介入的过程,即什么时候开始,什么时候结束。
感想
如果你有幸在通用平台上钻研过自定义状态处理,你发现它是构建在一个通用框架上的扩展,你需要了解这个框架,而框架则为了考虑所有场景,所以将其抽象到一个爹妈都不认的高度。你需要将你的业务问题套进去,这个学习和试错成本并不低,有时甚至是一个本末倒置的过程。
所以当你的业务是“杀鸡”问题时,切勿寻求“宰牛”方案,也不要轻信网上那些技术营销或大厂经验而投入Spark或Flink大坑。
合适的永远是最好的。
参考:
Flink基本原理 https://flink.apache.org/flink-applications.html
UDAFs https://spark.apache.org/docs/latest/sql-ref-functions-udf-aggregate.html
Spark State https://spark.apache.org/docs/1.6.1/api/java/org/apache/spark/streaming/State.html
Flink State https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/fault-tolerance/state/